
工作太忙加上懒,几年没有写blog了,去年买房所以顺手写了个爬武汉房地产网站生成一房一价表的爬虫,虽然在开盘之前就爬出来了备案价,但是还是没有挽救我在高点进去站岗了~~o(><)o ~~。。。。因为还有同事也要买房,后来就干脆优化了一下给同事用。现在随意总结一下,想到哪写到哪(:з」∠)_
关于框架
一般情况下爬简单的页面,python自带的urllib就够用了,如果是需要输入验证码登录的网站可以用requests库,保持cookies比较方便,用pytesser+tesseract识别简单的验证码也够用。
但是如果要爬批量的数据,最好还是用比较成熟的框架,比如说scrapy,处理数据方便&&很多现成的措施防止被ban。
之前用过一次scrapy,当时是因为刚买了烤箱加上痴迷烧烤,就爬了下厨房上面的烧烤菜谱,用wordpress搭了个烧烤网站(顺手画了个logo还买了个烧烤的域名,但是今年没续费已经过期了哈哈哈),图片存在七牛云上面(直接把下厨房图片的url传过去,把文件名拉回来就成),菜谱直接用xmlrpc传给wordpress,简单粗暴,用scrapy暴力搭一个网站分分钟(所以放弃的也快,放个尸体纪念一下夭折的它
很low的武汉房地产信息网站
这个网站真的很烂,随便怎么爬,都不会限制ip,就是爬的快了容易503而已。并且,网站结构清晰简单,十分适合想入门爬虫的童鞋练手。
爬虫版本们
最开始做第一个版本的时候,就是自己的一个一次性的需求:爬一个固定的楼盘,生成每栋楼一房一价的csv文件。所以starturl直接设置成楼栋表的页面(4.asp),按部就班的向下层一直遍历到房价页面(6.asp)就可以了,如下图流程。提取页面信息的话,其实xpath和css用起来差不多,有前端经验的人做起来一般都毫无压力。
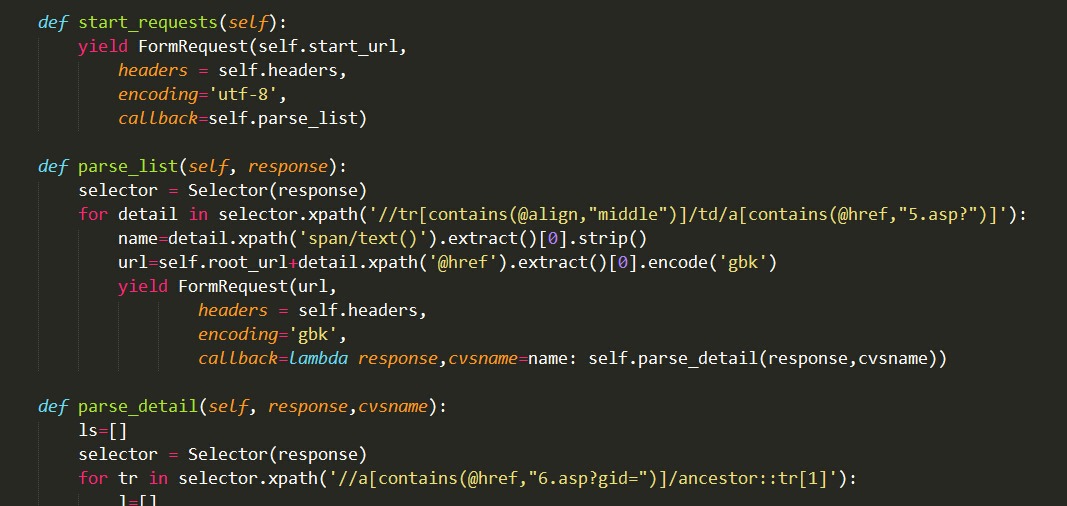 两个小tips:
两个小tips:
- request的回调方法,如果想传多个参数(比如要把房表页面的楼层单元等等传到后面),可以使用lambda,&&使用lambda的时候不能省略response参数;
- gid是很多个0的那种就不用请求了,那个就是没备案价的。
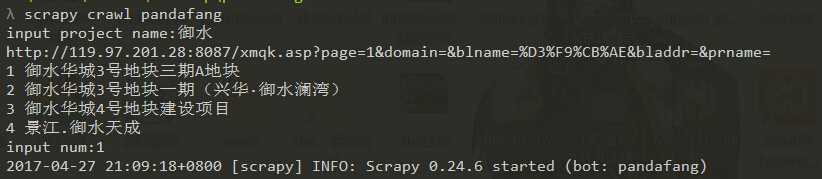
第二个版本我优化了一下,多爬了一个搜索页(xmqk.asp),这样可以直接输入楼盘名字搜索,再选择序号就会开始爬相应楼盘,如下图,省去第一个版本里面需要手工替换楼盘登记号(DengJh)的麻烦。由于scrapy貌似不支持实时请求返回结果,所以直接用requests爬的搜索页。顺便分享这个版本的源码,请叫我雷锋。
做第三个版本是因为想搞事情,把全站的楼盘房价信息都爬下来,玩一把大数据,顺手搭个网站玩。因为要爬大量数据,所以又搞了一些小优化:
- 实现了增量爬取,中断之后再爬的时候直接跳过有效数据,这样爬取过程中发现网站挂了的时候也可以歇一下,不用傻傻等爬虫低效的爬上几天几夜还不敢停。
- 再就是胆子小,这么大的访问量还是有点怕被请喝茶,所以加了中间件,随机换UA和代理,代理用的西刺免费的,偷懒直接用js生成配置串了,有需要的可以直接拿去用:
$("table#ip_list tr").each(function(i,dom){tds=$(this).children("td");if(tds.eq(5).text()=="HTTP")text+="{'ip_port': '"+tds.eq(1).text()+":"+tds.eq(2).text()+"', 'user_pass': ''},"})
再随便扯下网上开盘的事
最近武汉流行网上开盘,虽然极有可能还是内定了名额,但是说不定速度快还是能抢到呢是吧。所以写写chrome插件还是很有必要的。根据网站的类型,基本上有两个思路:
- 一种很low的,没有验证码也没有校验你选房流程是否规范的网站,可以直接模拟选房请求,差不多到点的时候,循环post数据就行。
- 另一种就是session全程记录用户操作,过程里面带验证码和回调的网站。这种网站,不要冒险,按照流程js模拟点击就好,模拟点击的时候,也注意做好判断条件,不要一不小心把别人网站dos了,然后就被说违规了。